

How to regulate copyright when it comes to artificial intelligence? In an interesting event organized by Web3 Allianceis exactly ChatGPT to ask yourself this question: the artificial intelligence of OpenAI indeed interviewed Lydia Mendolalawyer partner of the Portolano Cavallo firm, on copyright in the time of AI.
AI and copyright, ChatGPT interviews the lawyer Lydia Mendola
The Web3 Alliance is, quoting from their site, the “answer of those who want to face the challenge of Web 3.0 (metaverso, virtual reality, augmented reality, blockchain, AI) in a conscious way to fully seize the opportunities and limit the risks”. In an event organized in Milan, the consortium discussed one of the most debated topics ever: artificial intelligence.
A technology that is rapidly revolutionizing the world. As he explains in a chat on the sidelines of the event Andrew DeMicheliPresident of Web3 Alliance as well as CEO of Costa Diva Group: “If the internet revolution has taken twenty years to radically change the way we work, AI could do it in a quarter of the time: within five years it could become the new normal”.
The moderator and journalist Pepe Mother so he explains to us that he wanted to start using AI right away to do his job, asking ChatGPT to interview lawyer Lydia Mendola on the subject of copyright for artificial intelligence. They tried several times to give ChatGPT the same prompt, but it changed every time: so the effect would have been that of a human interviewer – even if the journalist in him couldn’t resist asking a few more questions.
Generative AI and copyright – ChatGPT’s interview with Lydia Mendola

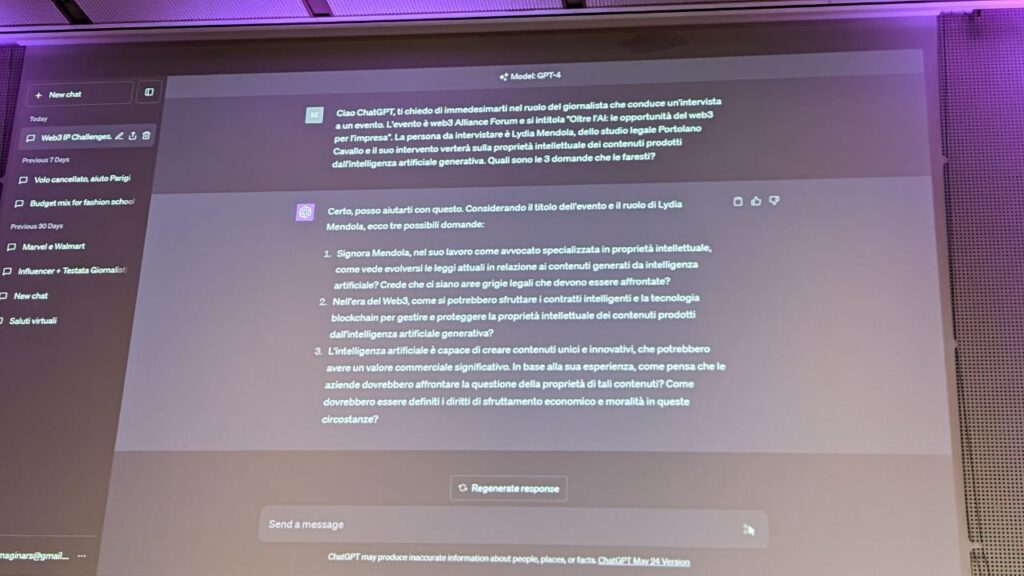
The prompt chosen by Pepe Moder was: “Hi ChatGPT, I ask you to immerse yourself in the role of the journalist conducting an interview at an event. The event is web3 Alliance Forum and is titled “Beyond AI: the opportunities of web3 for the enterprise”. The person to be interviewed is Lydia Mendola, of the Portolano Cavallo law firm and her intervention will focus on the intellectual property of the contents produced by generative artificial intelligence. What are 3 questions you would ask?
In real time, we saw ChatGPT (the GPT-4 based version) generate questions, taking into account the title of the lawyer role event. Which has been able to respond blow by blow to the AI.
From AI bias to copyright
ChatGPT asks: “Ms. Mendola, in your work as an intellectual property lawyer, how do you see current laws evolving in relation to AI-generated content? Do you believe there are legal gray areas that need to be addressed?”
The lawyer starts with a joke about ChatGPT’s bias: “I would start by saying that ‘Signora Mendola’ perhaps reflects a bit of sexism in the data, I would have expected at least a ‘doctor’.
He then goes on to explain that in intellectual property law there is no real regulatory vacuum in the management of AI, but “it leaves several gray areas. We have to figure out how adapt copyright regulations to AI-generated products.
“Does AI-generated content meet the minimum requirements to be protected by intellectual property? The US Copyright Office, which deals with the protection of original content created by users – it handles half a million applications a year – recently said, speaking of a comic whose images were from Midjourney, that they are not protectable. Content is protectable when it is original and has a creative character. The AI content, according to the Copyright Office, has no creative character: with the decision it said that what was created with Midjourney cannot be reproduced – the same prompt gives different results. And therefore it cannot be protected with copyright“.
What makes a product “original” and “creative”
This decision in the US led to a big discussion. “The creatives cheered on the decision, because it recognizes their role in the creative process. But companies that want to exploit this technology have arisen, because they cannot protect their own material created with AI. The Copyright Office a month later produced guidelines outlining how ratings vary on a case-by-case basis. And he said that, whether the author in the model puts creative value into the dataset or editingthe content may be protectable.”
So different types of AI could help produce AI-created but copyright-protectable content, according to the lawyer interviewed by ChatGPT. Who adds (on Pepe Moder’s input, this time) that “even the topic of training is a topic that involves copyright: It is currently unclear whether the AI was trained with products the author has given consent to use. Getty Images has claimed that some AIs (notably Stable Diffusion) were trained without the rights being granted. So even an author using this AI could be infringing on Getty copyright without knowing it. There is one exception though: data mining is allowed for the development of some AIs, but the author must have the possibility to opt out“.
How to protect AI copyright (if granted): ChatGPT interview with Lydia Mendola
ChatGPT’s second question on the subject of copyright and AI to the lawyer is: “In the era of the Web3, how could smart contracts and blockchain technology be exploited to manage and protect the intellectual property of content produced by artificial intelligence generative?”
The lawyer responds faster and more prepared even than AI: “Assuming that the contents of the AI are protectable, NFTs and the blockchain could certify the origin and subsequent circulation of a content. The entire content industry has seen technological revolutions that have changed the way content is distributed – let’s think of audiovisual streaming. But generative AI changes the paradigm with which these contributions are bornfor the first time.
Finally, ChatGPT’s last question is: “Artificial intelligence is capable of creating unique and innovative content, which could have significant commercial value. Based on your experience, how do you think that companies should address the issue of ownership of such content? How should the rights of economic exploitation and morality be defined in these circumstances?”
Mendola comments: “He’s clever, he reformulated the first question a bit”. But regarding the role of companies in these cases, she explains: “The company must be able to keep the data during generationbecause it will have to be able to demonstrate that he has not delegated the creative process to the machine but he made his own creative contribution. Otherwise, the contents will hardly be protected by copyright”.