

When we think ofartificial intelligence (AI) we think of something cold, logical, without prejudice. Many artificial intelligences, however, show instead prejudices e bias that reflect human ones. So let’s try to understand how it is possible that aartificial intelligence turns out to be bigoted.
Bigoted artificial intelligence
To understand how it is possible that an artificial intelligence is bigoted, we must first understand what we mean when we talk about AI. In reality this term indicates an entire discipline dedicated to understanding if, through computer systems, it is possible replicate or at least simulate the complex thinking of the human being.
The tools and technologies, both hardware and software, are many and different from each other. However, there is a set of methods, born at the end of the twentieth century but become popular in the last decade thanks to the effective possibility of putting them into practice, enclosed in the term machine learning (o automatic learning; ML In short). These learning algorithms, combined with the concept of neural network as a structure to be trained and which contains within it the actual artificial intelligence, they are the basis of many modern AI.
Machine learning
When developing a “by hand” algorithm in order to obtain from a certain input (eg the current atmospheric conditions) a certain output (eg the forecast for tomorrow), it is necessary to intimately understand the mechanisms of the algorithm and the necessary elaborations. A process that, in many cases, can result, very difficult, if not impossible, and which is even more difficult to generalize for every possible variation of the input. This is especially true when you want to recreate cognitive functionsas we still know very little about how our brains actually process certain information.
The ML reverses this situation. Ignoring the internal mechanics of the algorithm, it only requires a series of input-output pairs, some examples (in the jargon we say a training dataset). Starting from the inputs whose desired outputs are known, the ML process is able to adjust the internal variables of the algorithm. The result is a kind of AI capable, in the context of the entry and exit used for training, resist the right output even to inputs not used in training.
Let’s try to see an example. If we want an algortimo that can recognize the presence of a dog in an image, we can put ourselves there and brainstorm what actually in a pixel grid is a possible indicator of a dog’s presence. This is an extremely difficult task, especially with a view to creating a generalized algorithm capable of working with images that are also very different from each other. On the other hand, it is much simpler collect many images, with and without dog, properly labeled, and feed them to an ML algorithm.
The data problem
While ML seems almost magical in creating an AI algorithm, it presents several problems. What interests us for our initial question is one in particular: the quality of the algorithm is highly dependent on the quality of the training dataset.
As well as practical problems, how to get a tagged dataset quite expanded and diversifiedthe conceptual problem is that any bias present in the dataset is reflected in the resulting algorithm. The ML process will indeed generalize the examples, but if these examples contain bias of some kind, this too will be generalized.
AI (too) human
Somehow the problem isn’t even artificial intelligence, but human. The dataset of ImageNet, which contains 14 million tagged images and it is used in a lot for “visual” AI training, it super-presents people and scenarios from United States compared to other parts of the world, such as China and India. This leads to prejudicial results, where for example an image with a person dressed in a Western wedding dress is correctly labeled with “bride”, “dress”, “woman” or “wedding”, but a person wearing a wedding dress Indian falls under “performance” or “costume”.
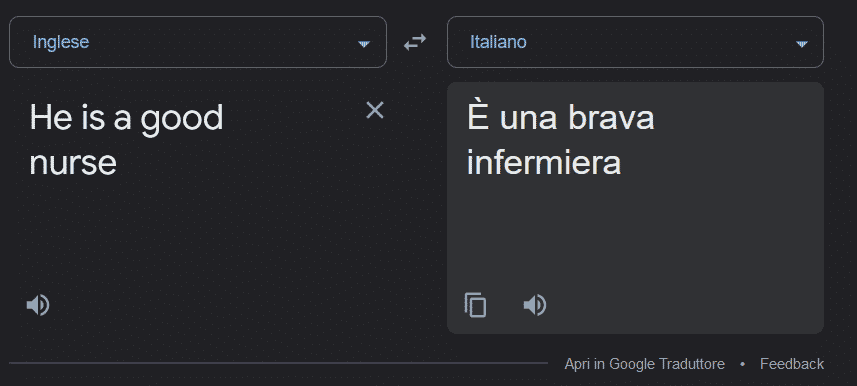 Nurse is translated to the feminine also specifying the masculine
Nurse is translated to the feminine also specifying the masculine
Another example concerns the translation. In translations between various languages, Google Translate tends to assume o even to change the gender of the subjects involved according to what is the most common and prejudicial expectation.
The examples above may seem trivial, but this type of over- or under-representation can have very serious consequences. Artificial intelligences used in medicine to identify skin cancers, and trained mostly with images obtained from Google with an automated program. Of these, less than 5% it belonged to people with dark skin. The algortimo then it has not even been tested on this population group.
A complex problem
The problem, as seen, it is widespread and complex. AI needs very large datasets to be trained, because the larger and more varied the dataset, the better the AI will perform. However, the already available datasets are often very centered on perspectives male e westernersif not really USboth from the point of view ethnic that cultural that linguistic.
Compose these datasets, which must be tagged by hand by students the da underpaid workers in contexts such as Amazon Mechanical Turk, requires a lot of time and resources, and higher quality and no bias are not always guaranteed. Finally, it doesn’t help lack of sensitivity (or incentives to be sensitive) that many companies and academic circles have for the problem.
The solution must necessarily involve a greater awareness of the problem and a transversal effort in trying to build expanded datasets, also diversified geographically, ethnically and from the point of view of gender, then making them available to everyone. Some researchers are already working in this direction, but there is still a long way to go.